
I receive a lot of questions from customers if they should implement LACP rather or not, so without further ado:
In this blog I’m going to talk about if it is a good idea to configure LACP between your ESXi hosts and the physical switched network? The Link Aggregation Control Protocol delivers enhanced features for a Link Aggregation Group (LAG), ensuring a stable connection between 2 network devices over multiple physical links by exchanging LACP-BPDU’s. Sound good right? And yes, from a network perspective it surely does! But from an vSphere ESXi hosts there are other “things” to think about, which I will cover in following chapters.

ESXi virtual switches and LACP
ESXi has 2 options when it comes to virtual networking: the vSphere Standard Switch (VSS) and the Distributed vSwitch (DVS). The VSS is ESXi local, which means it can only be managed from the ESXi host itself. Where the DVS can only be managed through the vCenter server, its configuration is being distributed to all connected ESXi hosts using Host Proxy Switches. The DVS offers several improvements over a VSS, like (for example) LACP support. The VSS does not support LACP.
When configuring LACP you have to configure the LAG on the DVS and have to manually add the physical NICS (pNIC or VMNICs) of each individual host to LAG uplinks (or you can do it scripted as you should).

The amount of uplink ports in a LAG have to be configured globally and this amount of LAG-uplinks are distributed to all Host Proxy Switches, which means that when 2 LAG uplinks are configured at the DVS/vCenter server level all hosts connected to that DVS will receive two LAG uplinks. The connected vSphere ESXi hosts cannot deviate from that amount of LAG uplinks.
The LAG as a logical link is being handled as an DVS-uplink itself, so you can use it to load-balance traffic between normal DVS uplinks and LAG uplinks.
The benefit is that LAG as logical link can utilize all the available bandwidth and you can add additional bandwidth by adding additional physical links. It can also help in case of failed physical connection, the connection will automatically be detected by LACP and will be thrown out of the logical link. This is what we call a Layer 2 high availability solution: the logical path is controlled by LACP and automatically scales when needed creating an optimal path between two devices.
Let me clarify the “logical link can utilize all the available bandwidth” feature: LACP is using IP Hashing for its load balancing algoritme, which means that a single network flow cannot exceed the bandwidth of a single physical connection.
In the worst case (example) you can end up having two elephant flows and one mice flow: The two elephant flows can reside on the same physical link and the mice flow on the other. The two elephant flows will have to share the available bandwidth of the same physical connection, resulting in poor network performance, while the mice flow has enough bandwidth available.
That’s just the nature of IP hashing.
Comparing Virtual Port ID and LACP
A DVS and/or VSS-switches offers multiple load-balancing options: by default load balancing based on Virtual Port id (sometimes called Source-MAC pinning) is being used on the VSS and DVS. It has the same drawback as IP hashing, but the good news is that having this type of load-balancing is that you do not have to configure the physical switch for layer 2 availability (LACP/IP hashing): A Virtual Machine is pinned to an uplink or an interface and it will stay there, as long as no failure occurs. When a failure on the pNIC occurs, the VM will be pinned to another available pNIC and (when configured properly). a RARP packet is being send to inform the physical switch so it can learn the MAC-address on this new interface, minimizing the outage time.
So let’s compare LACP/IP Hash and Source-MAC pinning/virtual port-id: they both offer the possibility to utilize the available bandwidth and both offer a form of physical interface resiliency, at the downside is that for LACP you need to manually configure LACP bundles on the physical switch AND on the DVS AND manually add the pNICs to the LAG (read: a lot of manual, prone-to-error configurations).
Compare LBT and LACP
A DVS offers the possibility to use the Load Balance Teaming (LBT)-load balancing option (= a good word for scrabble). You can see LBT as the enhanced Virtual Port ID load balancing option: It acts the same but with one mayor difference: It monitors the bandwidth utilization every 30 secondes and re-distributes the MAC-addresses (VMs) over the available pNICs when the bandwidth utilization is above the 75%. This will spread the bandwidth utilization over all available pNICs evenly. This will overcome the “pinning” problem which the “normal” Virtual Port ID load balancing option has. With LACP, it isn’t possible to distribute the load evenly over the available physical links: an IP address is pinned to a physical uplink. So in this battle against VMware vs LACP, this point is given to VMware as it offers a more enhanced feature compared to LACP.
Monitoring LACP on an vSphere ESXI host
So let’s continue with a operational task: Monitoring the LACP logical link.
Why is this important you may ask yourself? The answer to that question is quite simple: The more operational tasks are needed, the complexer the solution, the easier it is to make mistakes.
Keep in mind that with both Virtual Port ID and Load-Balanced Teaming (LBT) options, there is no configuration needed on the physical switch to enable the distribution of the VM workloads over the available physical NICs. Both teaming policies follow the networking standards and utilized all physical links by default (as long as they are active). So less configuration equals easier configuration, which lowers the operational complexity.
In the example below, I’m showing what is needed to monitor the LACP logical link between a VM and a switch:
In this example I’m assuming that the network cables are connected correctly and that LACP is also configured correctly.
Let’s start from the physical switch side.
From a physical switch perspective you can utilize the following command:
show port-channel brief
This command will show you the status of a LACP port channel:
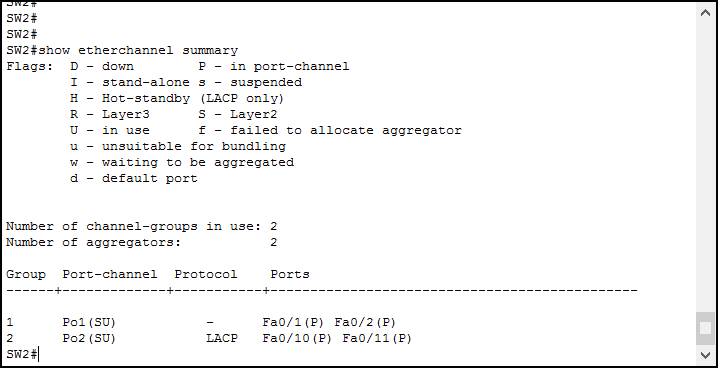
So as you can see here, is that LACP is configured as PortChannel 2 (PO2) and it is using layer 2 and is Up (status: SU), the configured ports are Fa0/10 and Fa0/11. Both ports are active (status:P).
If you have multiple ESXi host, each host has its own PortChannel ID. It is becoming a daunting task if you have a large amount of port channels, you will have to start tracking down the ports and the connected ESXi host. This piece of information is not show with this command. You can utilize CDP and/or LLDP or when those are not available, consult you (hopefully not outdated) networking documentation to track down the correct ESXi host. #prone-to-error
Monitoring LACP from a vSphere ESXi perspective is even a little bit harder.
The LACP configuration is being provisioned from the vCenter and distributed to the proxy switches hosted on the ESXI hosts: It is centrally managed. On the other hand: The LACP port channel status has to be monitored from the ESXi host itself. So if you have a large amount of ESXi hosts, you have to log into each individual ESX host to check the status.
You cannot check the LACP status from the GUI, you have the SSH into the ESXi host. Enabling SSH on a ESXi hosts is isn’t a best practice at the first place!
After logging in you have to execute the following command:
esxcli network vswitch dvs vmware lacp status get
You will receive a result like this:

Not a very nice overview if you ask me.
To summarize, you can see that both physical links (vmnic0 and vmnic1) have a status Flag of “SA”:
– it uses Slow LACPDU’s.
– it is Active.
You can state that monitoring the LACP LAG isn’t easy with VMware ESXi. The reason behind this is that LACP is only be integrated within ESXi because network admins just keep asking VMware to implement LACP. It just have been implemented as an afterthought as VMware ESXi offers good alternatives.
Using LACP with multiple physical switches.
In the above example we connected the ESXi host to one physical switch, which isn’t a best practice also: if the physical switch dies, you end up bare handed. Connecting a ESXi host to multiple switches imposes new challenges in regards to LACP.
LACP is using PDU’s (Protocol Data Units) to establish a logical connection between two (2) devices over multiple links. These devices will exchange PDU’s to see which links should be placed into the logical link (and which not). When a ESXi host is connected to multiple physical switches, the switches aren’t able to enumerate these PDU’s correctly. The switches work independently, have a separated management plane, which make them unusable for LACP. There is a solution to this problem called Multi-Chassis Link Aggregation Grouping (MLAG). With MLAG, two independent switches can build a LAG to a single device (or another MLAG) by acting as single device.
The switches needed to be interconnected to each other, which makes them able to:
– See if there neighbor is still alive. (usually over a separated physical link called the keepalive link)
– Send/receive packets to the other physical link (over the neighboring switch).
Below a schematic overview of a MLAG to another switch
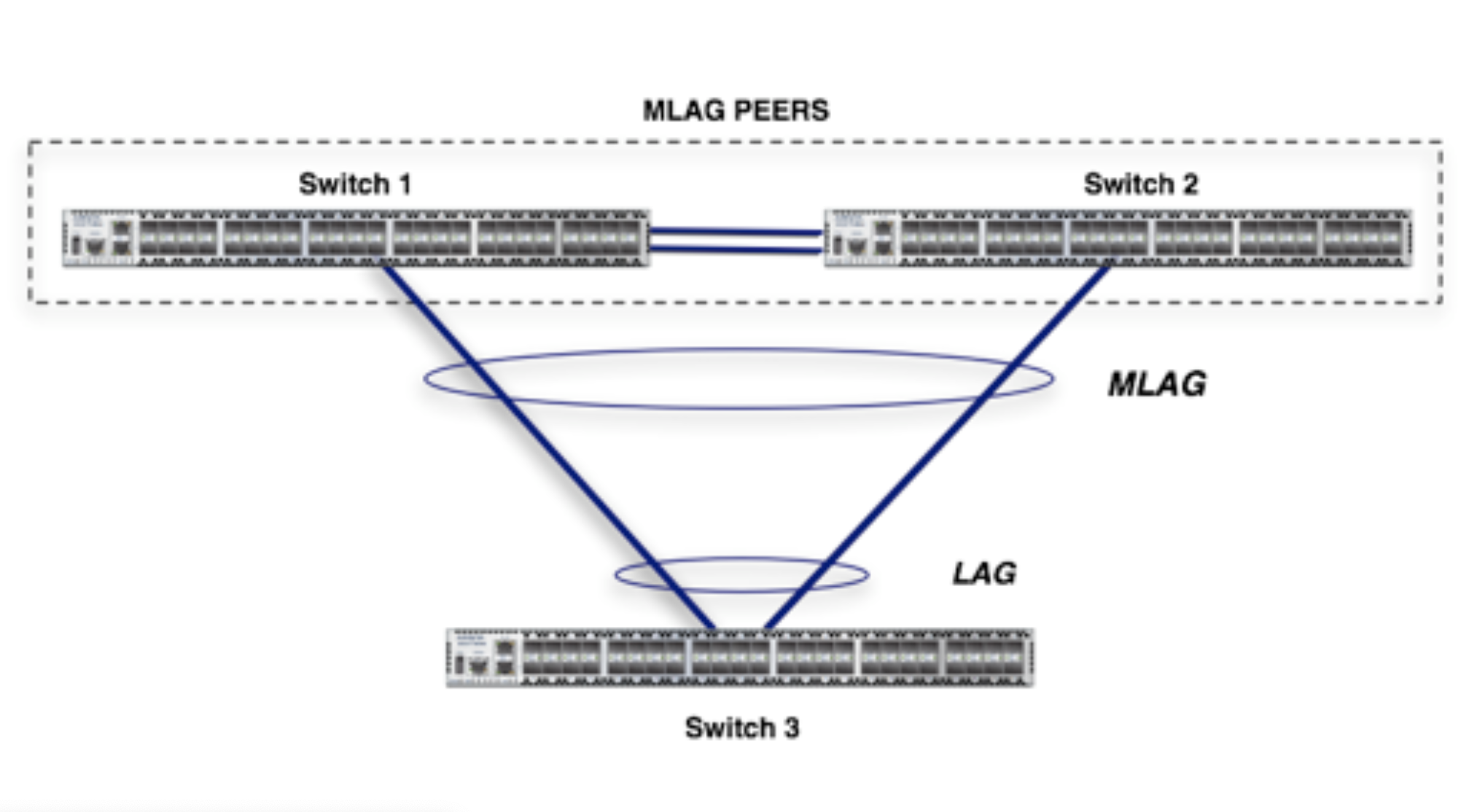
In the network world MLAGs are very common these days, as they overcome traditional network problems caused by loops. They still require a manual configuration AND the configuration on both MLAG peer switches must be exactly the same, which again imposes operational challenges, because you now have three (3) devices that need to be configured correctly in order to work. The amount of dependencies are constantly growing (with MLAG), but without an actual need as Virtual Port ID and LBT do not need LAG and/or MLAG. You can connect you ESXi host to two (or more) independent switches, use either Virtual Port ID or LBT and you are good to go.
Spanning Tree ?
A little bit off-topic.
You can now ask yourself: But how about the traditional network problems caused by loops with ESXi? The answer is simple: The virtual switch within ESXi, by default, prohibits loopings. In the physical network you use Spanning Tree to disable redundant links which protects agains loops: With ESXi there is no need for Spanning Tree and should be set to mode “portfast”, which essentially disables spanning tree for the ESXi host.
Conclusion.
With the available load-balancing algoritmes available in vSphere there is no need for a complex, prone-to-error LACP configuration, as VMware offers good (and some better) options from a configuration, utilization and availability perspective.
So why do some customer still use LACP you might ask? Usually it is because of the a lack of (VMware-) knowledge and add up the good experiences with LACP from the past by network admins.
LACP between switches and bare-metal servers are still a very good option, but VMWare offers some enhancement which neglect the use of LACP for vSphere environments.

April 29, 2020
While I do agree LACP has its challenges with ESXi. The conclusion of the article is in error. Once setup the performance of LACP is better. Not only that LACP can detect upstream network issues LBT is oblivious to. LACP is also the VSAN recommendation because VSAN cannot utilize LBT.
See https://storagehub.vmware.com/t/vmware-r-vsan-tm-network-design/static-lacp-with-route-based-on-ip-hash/
April 29, 2020
I’m disagreeing with ALL your statements:
– Starting with “performance of LACP is better”: LACP uses IP hashing, were a single flow cannot exceed the bandwidth of a physical link (which is the same for Virtual Port ID and LBT). So no performance gain for LACP here.
LBT even offers performance improvements as it allows to migrate traffic flows to a lower utilized physical link. This point goes to LBT.
– Regarding the “detection of upstream network issues”: LACP uses only LACPDU handshakes for its upstream device issue detection, LBT depends on the link state (by default) or it can also utilize beacon probing. Again, both solution provided upstream device issue detection.
– “LACP is also the VSAN recommendation because VSAN cannot utilize LBT”, this statement is completely wrong as per https://docs.vmware.com/en/VMware-vSphere/6.7/com.vmware.vsphere.vsan-planning.doc/GUID-031F9637-EE29-4684-8644-7A93B9FD8D7B.html
LBT (Route based on physical network adapter load) is supported and the recommended option. This recommendation is part of the VMware Validated Design: https://docs.vmware.com/en/VMware-Validated-Design/5.1/sddc-architecture-and-design/GUID-A60671C3-BBBE-4A87-A55F-0243A003F4F7.html
July 10, 2020
This is a really useful article that addresses some of the issues I’m currently trying to resolve around undetected upstream link failures going undetected by VMs. I’ll do some more reading on LBT and Beacon Probing. Many thanks!
September 30, 2020
I find the conclusion erroneous.
1) Performance
Agree about the nature of IP hashing. But this doesn’t make LBT any better since you could end up > 2 elephant flows clogging the physical links in the same manner. However, with LACP you can specify port-group specific hashing which can be 5-tuple or 5-tuple+MAC or other strategy to achieve better load balancing.
vSphere DVS allows you to specify the same VLAN for different port groups with different hashing methods. Look under PortGroup properties.
LBT can be marginally better in the use case where you have 2 elephant flows in the event they happen to collide because of hash methodology used. As I mentioned above, this can be avoided with some planning.
LBT is not network aware. What this means is, the host can load balance the traffic on its side but the network is oblivious to this. Which means the network will only send return traffic on the physical link on which it learned the VM MAC.
Lets say you have two switches connected to a Host. LBT pinned traffic from VM A to Switch 1 in VLAN 10.
Now VM B on Host 1 in VLAN 20 presented itself on Switch 2 because of LBT. For traffic to flow from VM A to VM B, it will have to traverse the inter-switch link. This will not only increase latency, it also has the potential to trash your inter-switch bandwidth.
With LACP however, the switch is aware of host load-balancing and will localize traffic where possible. What this means is, in the above example, both the switches (assuming they are configured in MLAG) would be aware of VM A and VM B MACs. Therefore traffic originating from VM A destined to VM B arriving at Switch 1 will be forwarded on the local switch port. The switches will actively try to avoid forwarding traffic over inter-switch MLAG channel. This is desirable because it keeps latency low and also avoid using up inter-switch bandwidth unless necessary.
Further, any performance gains that LBT provides between the host and the connected switch are likely to disappear if the traffic has to traverse inter-rack switches, since inter-rack switches are likely to use LACP or ECMP (L3 LACP) for inter-switch traffic load-balancing. So without proper network engineering, your elephant flows could end up colliding in the upstream network elsewhere negating any benefit.
2) High Availability
Indeed LBT detect link failures and can use beacon probing. But you get the same with LACP with both host and the network being aware of each other and reacting to failures on either side because of the LACP protocol. With LBT, the network is not aware of soft failures on the host side and cannot react to it.
3) Security
LBT is a loop topology. If you don’t configure BPDU guard on your network, a single rogue VM can bring down your entire L2 broadcast domain. LACP avoids this since it presents a virtual mac on both ends of the link and switching/forwarding is localized.
4) VSAN Performance
It is beyond doubt that VSAN performs better with LACP than with LBT when you have > 2 VMs. This is an established fact. Claiming anything otherwise would be negating laws of physics 🙂
5) VVD Recommendation
It is just a recommendation. VVD cannot account for your networking, your performance requirements or for the nature of traffic flows and security. You have to do that yourself with solid network engineering.
I would only suggest that anyone only use LBT for small 4 node setups connected to a single switch.
6) LACP Configuration
I would agree that LACP configuration on the switch and the host is relatively more work compared to LBT. But only slightly. And this can be mitigated with automation scripts and good planning.
In summary, if you want quick and easy use LBT. If you want performance, availability, security at scale .. LACP is the answer. The installed base of LACP capable switches in terms of $$s is more than the market cap of VMW 🙂
VMworld 2020 is in session. If you can find a decent VMWare network engineer and get them to refute my points above, I will send you 12 packs of finest beer (144 beers) from California 🙂
You can reach me at my email.
September 30, 2020
Hi Cave,
I’m happy to elaborate with you on your statements:
1)
– yes with LBT 2 elephant flows can end up on the same link, but only for a limited time: it will be migrated to another link within 30 seconds de-clogging the link.
– Yes, you can configure a load balancing policy per VDS portgroup, but you cannot configure the LACP hashing mechanism per VDS portgroup (these are two different thinks).
– I also think there is not better hashing method than a dynamic one (which LACP can’t offer)
– That being said, having to dive into the settings of each individual port group setting makes your environment an administrative and operational hell: Keep It Simple Stupid (KISS), by just selecting LBT and let that mechanism figure it out for you.
– Regarding the integration between the hosts and the physical network, you’re example assumes that the L3 point is on the switch where the host is connected to: This is true in spine-leaf architectures, but likely not true in traditional 3-tier (core, distributed, access) architectures (which are still around). In these situations the traffic has to traverse multiple links (trashing latency and the link bandwidth on the way also).
– Ok, I have to agree that LCAP does optimize the utilization of the inter-switch link when using a MLAG/VPC, but again it’s only beneficial in specific use cases where the L3 point is on the connected switch (see my previous point).
– Demolishing the benefits of LBT by saying that the network is using LACP/MLAG, is a wrong assumption (I think): The benefits totally depend on the overall bandwidth availability between the physical switching and routing components. It should not only depend on the used link aggregation/loop preventing protocols.
2) Agree (but with vSphere it’s usually a VM problem instead of a network problem: These problems can be resolved by VMware HA automatically). LACP doesn’t have to resolve anything here.
When it is a physical network failure, beacon probing can solve the problem also.
(no winners or losers here if you ask me).
3) Agree, LACP is a loop preventing mechanism (by creating a single logical link) and yes, when not using LACP you need to configure SPT portfast and BPDU guard on the switch ports which connect to the ESXi host: this is a more than a decade old recommendation from VMware. (PS you can configure the BDPU filter on the VDS since 5.1, mitigating this problem).
4) Agree, see: “https://storagehub.vmware.com/t/vmware-r-vsan-tm-network-design/dynamic-lacp-multiple-physical-uplinks-1-vmknic/”. Yes LACP offers better performance and availability with VSAN (because it used a single VMkernel interface), but the downside is less flexibility and added complexity (again: KISS).
PS you can deploy multiple VSAN-enabled VMkernel interfaces .. (which I also would not recommend)
(I think you were referring to my answer on the statement that LBT wasn’t supported with VSAN .. I’ve said nothing about LACP was a lesser option for VSAN)
(again no winners or losers here)
5) VVD (and VCF for that matter) is not a set of recommendations anymore, they have become prescriptive.
DIY datacenters are a thing of the past, fully validated (software defined) datacenters (like VVD and VCF) are how things roll these days. Things have been shifting to validated designs as the DIY datacenters introduced complexity (and a lot of operational troubles, with outages as a result).
6)
– First point :-“you can automate that”. Yes, you can automate the deployment (with careful planning), but who’s doing the troubleshooting when needed? again: KISS > see my second point
Second point: There is a people and process factor that needs to be taken into account. ESXi is usually not managed by the network team only, its being managed by the server team (who usually don’t have any clue about configuring LACP): it abracadabra for them.
Ok, I know this is an assumption but it’s reality at the same time: As a configuration is divided over multiple team, shit will hit the fan somewhere/somehow due miscommunications/misalignments. LBT is more forgiven in this case.
– “The installed base of LACP capable switches in terms of $$s is more than the market cap of VMW” is like comparing apples to oranges and saying that oranges are the better solution. Muh ,,
My conclusion:
LACP could technically be better, but the operational complexity it introduces has made it impossible to find it anywhere in any of the VMware validated designs (VVD and VCF) and or recommendations. Companies want validated design these days, thanks to their operational simplicity.
I’m happy to receive 12 packs of your finest beers, thanks 😉
February 24, 2021
[…] LACP and vSphere (ESXi) hosts: not a very good marriage […]
March 13, 2021
LACP is a load balancing policy which directly fights with vMotions Binding Policy. If a LACP link goes down during a vMotion, the vmotion fails. LACP therefore induces a single point of failure. LACP also means every time there is a upstream network glitch the VMware Admin’s will have to engage the networking team before they can perform even the most basic diagnostics beyond ping. LACP is the opposite of KISS.
February 10, 2022
Who uses yellow font color on “blue” background 🙁
Regarding ESX DS LACP and SWITCH LACP, I noticed, that after reboot HP blocks LACP ports as it doesn’t receive any LACPs BPDUs. Solution from vmware is to restart physical port of VMware, which make sense as it will send LACP BPDUs.
May 6, 2022
A great article and discussion…
@vVikingNL Is LACP or LBT can create a 2Gb or 4Gb network interface(2 or 4 NICs teaming) for VMs use?
May 6, 2022
Sadly both options (LACP and LBT) doesn’t allow you to create full 2 or 4 Gb virtual NICs for VMs.
LACP can aggregate physical NICs into a larger (2 or 4 GB) logical NIC, but this is not realistic from a bandwidth standpoint: LACP uses a algorithm to distribute the traffic over both physical NICs, but does this in such a way that it’s almost impossible to fully utilize all links (nor isn’t there any other solution available that can achieve this).
You should question yourself, why do you want attach a 2 or 4 GB virtual NIC to your VM? Is your VM really that bandwidth intensive?
May 6, 2022
Wonder if I use a NAS as NFS storage to host multiple VMs, if the bandwidth between ESXi and NAS is only 1Gb it obviously is too weak on the bandwidth? Is LACP or LBT can help with it?
May 25, 2022
“#prone-to-error” ….false
If y’all having trouble locating an ESX host because you have too many port-channels, you need to learn about ARP and MAC tables.
Even with outdated documentation, port descriptions (and no LLDP/CDP) it only takes 5 secs to find a host. In Cisco Nexus land, it looks like this:
sh ip arp | i
— above outputs MAC address associated with the supplied IP
sh mac ad | i
— above outputs the interface on which the specified MAC address is learned
#errorproof
May 25, 2022
Why should you care to make port channels in the first place?
January 21, 2023
Would LACP in a large VMware environment over time cause an increase in TCP Retransmissions?
January 22, 2023
Not a all. TCP retransmission are caused by packets which are lost during transit and must be resend. This is usually due faulty cabling: check for CRC errors on interfaces. Lacp bundles multiple link together, providing high availability
January 22, 2023
Just curious. Came across this site after working long hours trying to determine high level of TCP malformed packets and retransmissions across our server VLANs. Network team says VMware or OS issue and so we (VMware and OS team) are coming up empty. Thanks.
January 22, 2023
Aaaah fingerpointing never solved a problem, only facts: my advice is to do some packetcaptures on the esxi hosts and the connected switches
March 23, 2023
sho int trans details might help too if optical
BTW, LACP is only recommended for port groups with highly bandwidth intensive needs like streaming 4K VSS. Even then, the lift is minimal unless you’re still running a ton of 1 GbE ports. It’s 2023, so the better option IMO is to upgrade to 10 or 25 GbE ports.
March 7, 2023
Great article from my network admin’ perspective as I’ve only seen LACP based port-channels myself for host connectivity. So what would be the approach here for the physical switch interface configuration then if not using a LACP port-channels, just individual trunk ports with no form of LAG or bonding?
March 7, 2023
You are correct: just normaal individual trunk ports with spanning tree portfast configured.
October 16, 2023
Hi, Thank you for the article! I’ve been trying to learn the correct way to connect my new environment. I have two switches that are (mlaggged/peered) to each other. I will have new servers with two 25Gbps nics on each box. I will connect one 25G link to sw1 and the other to sw2. That part seems obvious. I was thinking of lacp but after reading on the net I decided against it. The point I’m trying to clarify right now is do I do an active/active connection with the 2 nics or active/passive? active/active seems the obvious choice since it will give 50G uplink instead of 25G. Yet lacp also seemed obvious which it turns out it wasn’t.
November 29, 2023
I would recommend a active/active configuration (not lacp): You will still get 2x 25Gb of bandwidth.
November 9, 2023
without lacp on switch/host end, if switch is MLAG two swith, the esxi with dedicated vmotion vmk# in vds won’t work won’t work. so how? to use legacy stacking switch with single control plane, then how to maintain the network upgrade?
lacp with MLAG with two control plane is much better from network maintenance perpective, and also good for vsphere. even through config level more error-prone.
November 29, 2023
In my opinion “keep it simple” is the answer:
When you are going to execute an switch-upgrade, the switch interfaces will go down and the ESXi host will detect the failure and automatically failover to the remaining NIC which is connect to the other switch: No need for a LAG here.
Configuring LACP will only introduce complexity and increase the error rate .. keep away such a complexity when using ESX!